
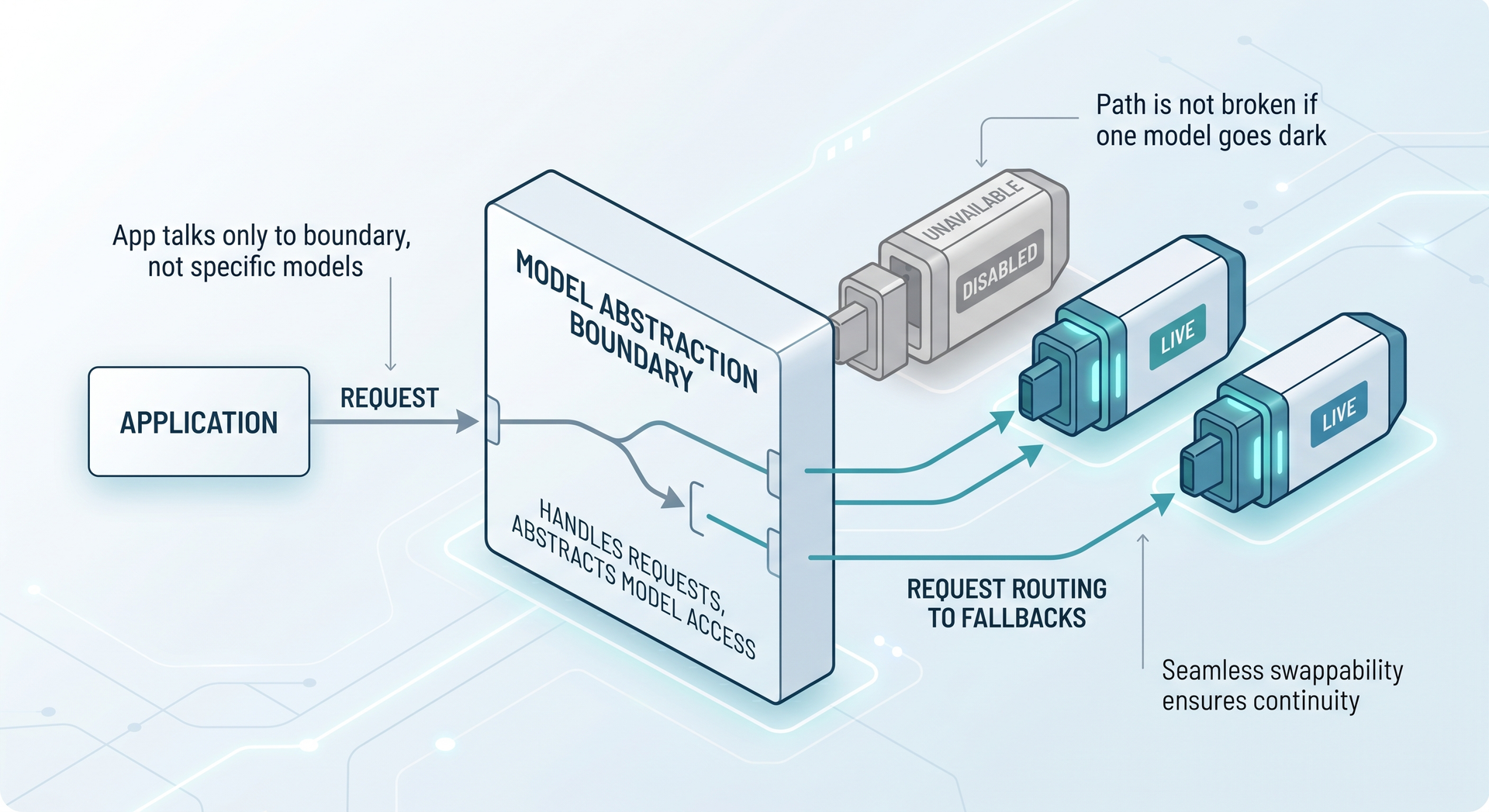
If one provider decision can take your product down, route every model call through a single boundary and treat the model ID as runtime configuration, not a hardcoded constant. Behind that boundary, keep an ordered list of models and fail over to the next when the active one returns an availability error. That pattern is an LLM fallback layer, and it is what separates a feature that survives a sudden model shutdown from one that does not.
This targets the Anthropic TypeScript SDK and any OpenAI-compatible gateway. Code examples use current Claude model ids as of June 2026: claude-opus-4-8, claude-sonnet-4-6, and claude-haiku-4-5-20251001.
TL;DR: route every model call through one boundary
Put one provider boundary between your app and any model. The application asks that boundary for a completion and passes intent (the prompt, the token budget), never a model ID. Model selection lives in configuration: a primary model and an ordered fallback chain you can change without touching feature code. The boundary fails over only on availability errors (the model is gone, overloaded, or rate-limited), and never retries a request the provider rejected as malformed, because retrying a bad request burns the whole chain for nothing. Build this as a thin in-process layer when you call one or two providers; reach for a gateway like LiteLLM, OpenRouter, or Vercel AI Gateway once you call several. The model ID is config, not a constant.
What concretely broke when Fable 5 and Mythos 5 went dark
On 12 June 2026, Anthropic received a US government export-control directive at 5:21pm ET ordering it to suspend all access to Fable 5 and Mythos 5 for any foreign national, including foreign nationals inside the US and its own non-citizen employees. The only way to comply within hours was to disable both models for every customer. Anthropic described the trigger as a narrow, non-universal jailbreak and said that if the same standard were applied across the industry, it "would essentially halt all new model deployments for all frontier model providers." You can read Anthropic's statement in full.
Here is the part that matters for how you build. Every other Anthropic model stayed up. A team whose code said model: 'claude-fable-5' in a route handler returned errors to users until somebody shipped a code change, ran CI, and deployed. A team that read the model ID from configuration changed one value and pointed the same call at claude-opus-4-8. Same outage, same provider, two completely different incident timelines.
The lesson is not "Anthropic is risky." It is that model availability is a production dependency you do not control, and you should architect for it the way you already architect for a payment API that can 503. A hardcoded model ID is the single point of failure.
Why a hardcoded model ID is a single point of failure
The fastest way to ship an AI feature is to call the SDK directly in the handler that needs it. Its model lives right there in the call, the response shape is whatever that provider returns, and it works on the first try. That is exactly the shape an AI assistant generates when you ask it to "summarize the ticket with Claude," the same demo-grade default catalogued in AI-generated React code, 9 patterns that fail in production, and it is the shape that broke on 12 June.
src/features/tickets/summarize.ts
import Anthropic from '@anthropic-ai/sdk'
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY })
export async function summarizeTicket(ticket: string): Promise<string> {
const response = await anthropic.messages.create({
model: 'claude-fable-5',
max_tokens: 512,
messages: [{ role: 'user', content: `Summarize this support ticket:\n\n${ticket}` }],
})
const block = response.content[0]
return block.type === 'text' ? block.text : ''
}
Two design decisions are fused into one function here, and that is the problem. The model ID claude-fable-5 is welded to the business logic of summarizing a ticket, so the only way to change the model is to edit, review, and redeploy this file. Worse, the provider client is instantiated inline, so the same coupling repeats in every feature that calls a model. When Fable 5 went dark, this function did not degrade. It threw, and it kept throwing until a human intervened.
The deeper issue is that the response handling is provider-specific too. That response.content[0].text access assumes the Anthropic message shape. Swap to another provider and the parsing breaks alongside the model name. The naive integration couples three things that should move independently: which model runs, which provider client makes the call, and how your app reads the result. Decouple them and a shutdown becomes a config change.
A model-agnostic provider interface in TypeScript
The goal is one call signature your whole app uses, with the provider details hidden behind it. Your features ask for a completion in terms they own (a prompt, a token budget) and get back a plain string plus the metadata they care about. Which model produced it, and through which SDK, is the boundary's concern.
One call signature, many backends
Start with the contract. Every provider in the system implements the same interface, so the rest of the app depends on the interface and never on a concrete SDK.
src/ai/provider.ts
import Anthropic from '@anthropic-ai/sdk'
export interface CompletionRequest {
prompt: string
maxTokens: number
system?: string
}
export interface CompletionResult {
text: string
model: string
}
export class ModelUnavailableError extends Error {
constructor(public readonly model: string, cause?: unknown) {
super(`Model ${model} is unavailable`)
this.name = 'ModelUnavailableError'
this.cause = cause
}
}
export class BadRequestError extends Error {
constructor(message: string, cause?: unknown) {
super(message)
this.name = 'BadRequestError'
this.cause = cause
}
}
export interface ModelProvider {
complete(model: string, request: CompletionRequest): Promise<CompletionResult>
}
export class AnthropicProvider implements ModelProvider {
private readonly client: Anthropic
constructor(apiKey: string) {
this.client = new Anthropic({ apiKey })
}
async complete(model: string, request: CompletionRequest): Promise<CompletionResult> {
try {
const response = await this.client.messages.create({
model,
max_tokens: request.maxTokens,
system: request.system,
messages: [{ role: 'user', content: request.prompt }],
})
const block = response.content[0]
const text = block && block.type === 'text' ? block.text : ''
return { text, model }
} catch (error) {
if (error instanceof Anthropic.APIError) {
if (error.status === 400) {
throw new BadRequestError(error.message, error)
}
if (error.status === 404 || error.status === 429 || error.status >= 500) {
throw new ModelUnavailableError(model, error)
}
}
throw error
}
}
}
The interface is the entire point. complete takes a model ID as an argument rather than baking it in, so a single provider instance can drive any model the provider serves. The Anthropic-specific knowledge, the messages.create call shape and the content[0].text parsing, lives in exactly one class. Everything downstream works with CompletionRequest and CompletionResult, which carry no provider vocabulary at all.
The translation of provider errors into two of our own error types is the load-bearing decision. A 404 (model not found, which is what a disabled model returns), a 429 (rate limited), or any 5xx becomes a ModelUnavailableError, the signal that says "try the next model." A 400 becomes a BadRequestError, the signal that says "stop, this request is broken and the next model will reject it too." We will lean on that distinction in the fallback layer. Hold onto it.
Model selection as configuration, not code
With the interface in place, model choice becomes data. The chain that broke on 12 June should be editable without opening a feature file, ideally from environment configuration so you can change it per deploy or even at runtime.
src/ai/config.ts
export interface ModelChain {
primary: string
fallbacks: string[]
}
function parseChain(value: string | undefined, fallbackDefault: ModelChain): ModelChain {
if (!value) return fallbackDefault
const ids = value.split(',').map(id => id.trim()).filter(Boolean)
if (ids.length === 0) return fallbackDefault
const [primary, ...fallbacks] = ids
return { primary, fallbacks }
}
export const ticketSummaryChain: ModelChain = parseChain(process.env.TICKET_SUMMARY_MODELS, {
primary: 'claude-opus-4-8',
fallbacks: ['claude-sonnet-4-6', 'claude-haiku-4-5-20251001'],
})
The chain reads from TICKET_SUMMARY_MODELS as a comma-separated list and falls back to a sane default if the variable is unset. On 12 June, a team running this would have set TICKET_SUMMARY_MODELS=claude-opus-4-8,claude-sonnet-4-6,claude-haiku-4-5-20251001 and shipped nothing. The model that vanished is simply absent from the list.
Notice the chain is named per use case rather than global. Ticket summaries can run on a cheaper model than, say, code generation, so each feature owns its own ordered preference. The configuration is where product decisions about cost and quality live, separated from the mechanism that executes them. That separation is what lets a non-engineer change the model in an incident with a single environment variable.
A typed fallback chain that fails over on availability, not just rate limits
Most fallback code people write only catches rate limits. That is the common case, so it is the one tutorials show. The 12 June shutdown was not a rate limit. It was a model that returned a 404 because it no longer existed, and a fallback layer that only retries on 429 would have sailed straight past the one error that mattered. The layer has to treat "the model is gone" and "the model is throttling you" as the same class of recoverable failure, and treat "your request is malformed" as a hard stop.
src/ai/client.ts
import {
type ModelProvider,
type CompletionRequest,
type CompletionResult,
type ModelChain,
ModelUnavailableError,
BadRequestError,
} from './provider'
export class AiClient {
constructor(private readonly provider: ModelProvider) {}
async complete(chain: ModelChain, request: CompletionRequest): Promise<CompletionResult> {
const models = [chain.primary, ...chain.fallbacks]
let lastError: unknown
for (const model of models) {
try {
return await this.provider.complete(model, request)
} catch (error) {
if (error instanceof BadRequestError) {
throw error
}
if (error instanceof ModelUnavailableError) {
lastError = error
continue
}
throw error
}
}
throw new ModelUnavailableError(
chain.primary,
new Error(`All models in the chain were unavailable. Last error: ${String(lastError)}`),
)
}
}
The loop walks the chain in order and returns the first success. A ModelUnavailableError is recorded and the loop moves to the next model, which is the failover. A BadRequestError rethrows immediately, because a request the provider considered malformed will be just as malformed for every other model, and retrying it down the whole chain wastes time, tokens, and money while the user waits. Any error type we did not classify also rethrows, because silently failing over on an error you do not understand hides bugs.
Wiring it into the feature replaces the hardcoded call with a request the boundary fulfills.
src/features/tickets/summarize.ts
import { AiClient } from '@/ai/client'
import { AnthropicProvider } from '@/ai/provider'
import { ticketSummaryChain } from '@/ai/config'
const client = new AiClient(new AnthropicProvider(process.env.ANTHROPIC_API_KEY ?? ''))
export async function summarizeTicket(ticket: string): Promise<string> {
const result = await client.complete(ticketSummaryChain, {
prompt: `Summarize this support ticket:\n\n${ticket}`,
maxTokens: 512,
})
return result.text
}
The feature no longer knows what a model ID is. It knows it wants a summary, it knows its token budget, and it trusts the boundary to pick a live model. Compare this to the version at the top of the article: the business logic is identical, but the failure mode changed from "throws until a human deploys" to "transparently degrades to the next model in the chain." That is the whole return on the abstraction.
One caveat worth stating plainly. This chain is Anthropic-to-Anthropic, which is the realistic fast fix on shutdown day because every model shares the same SDK and the same response shape, so failover is free of translation. The moment a fallback target is a different provider, you need an adapter that normalizes the request and response, which is the next section's trade-off. Failover within one provider is cheap; failover across providers is a project.
Build it yourself or adopt a gateway?
Once you accept that model selection belongs behind a boundary, the next question is who owns that boundary. You can keep the thin in-process layer from the previous sections, or you can route through a managed AI gateway that gives you a unified API across providers and a fallback chain as configuration. By mid-2026 most enterprise teams call several model providers, so a vendor-neutral abstraction has become the default rather than an exotic choice. The three gateways teams reach for are LiteLLM, OpenRouter, and Vercel AI Gateway.
Here is how the options compare on the dimensions that decide it.
| Dimension | DIY layer | LiteLLM | OpenRouter | Vercel AI Gateway |
|---|---|---|---|---|
| Setup cost | A few files, no infra | Self-host the proxy or run as a library | API key, no infra | API key, tightest on Vercel |
| Provider coverage | What you adapt by hand | Broad, many providers normalized | Broad catalog behind one API | Broad, managed routing |
| Fallback control | Total, you write the loop | Configurable routing and retries/fallbacks | Automatic model routing and fallback | Managed failover policies |
| Lock-in | None, it is your code | Low, open source you can self-host | Medium, routed through their API | Higher, strongest inside Vercel |
| Observability | You build it | Built-in logging and spend tracking | Dashboard and usage analytics | Dashboard and usage analytics |
The DIY column is the layer you already saw. You own every line, there is no new network hop, and there is no third party in your request path. The cost is that cross-provider normalization and observability are now your job, and that job grows with every provider you add.
When to pick each comes down to provider count and who you want maintaining the routing. Build it yourself when you call one or two providers, want zero added latency and zero new dependency, and value full control over exactly when failover fires. Reach for LiteLLM when you want broad provider coverage with the option to self-host and keep lock-in low, which suits teams that are cost-sensitive and infrastructure-comfortable. Reach for OpenRouter when you want the widest model catalog behind a single key with the least setup and are happy to route through a hosted API. Reach for Vercel AI Gateway when you are already on Vercel and want managed failover and observability with the least wiring. The honest default for a small team is to start with the in-process layer and graduate to a gateway when the provider count crosses two or three and you find yourself rebuilding spend tracking and unified logging by hand. That wrapping-a-flaky-dependency instinct is the same one behind using RTK Query the right, scalable way: centralize the awkward integration once so the rest of the app stays clean.
What a fallback layer cannot save you from
A fallback layer keeps your feature responding when a model disappears. It does nothing about whether the response is any good. This is the part teams skip, and it is where the quiet failures live.
The first gap is prompt and output drift between models. A prompt tuned against Opus 4.8 can return differently shaped output on Sonnet 4.6 or Haiku 4.5, and a cross-provider fallback to GPT-5.5 or Gemini 3.1 Pro widens that gap further. If your code parses the model's output as JSON, or depends on a specific tone or structure, a silent failover can hand downstream code a shape it was not built for. The boundary stayed up; the contract quietly changed.
The second gap is evaluation. Knowing whether a fallback model is acceptable means running the same evals against every model in the chain, not just the primary, before you ship. Without that, your fallback is a guess that you will only test for the first time during an outage, which is the worst possible moment to discover that Haiku 4.5 mangles the format your invoice parser expects.
The third gap is cost and capability. Models in a chain rarely cost the same per token, and they rarely have the same context window or tool-use behavior. A failover from a small model to a large one can multiply your bill, and a failover from a large-context model to a smaller one can truncate a prompt that fit a moment ago. Capability gaps cut both ways, and the fallback layer is blind to all of it. A fallback layer is a resilience tool, not a quality or cost guarantee.
A resilience checklist for your AI layer
Run this against any feature that calls a model before it ships to a paying user.
- Route every model call through one boundary. No feature file names a model ID directly.
- Make model selection configuration. The primary and the fallback chain are editable without a code change, ideally from environment variables you can flip per deploy.
- Classify provider errors into two buckets: availability errors (404, 429, 5xx) that trigger failover, and bad-request errors (400) that must stop the chain immediately.
- Order the chain by cost and quality per use case, not globally. Summaries and code generation deserve different chains.
- Run your evals against every model in the chain, not just the primary, so a failover does not silently degrade output quality.
- Log which model actually served each request. When you fail over, you want the metric and the breadcrumb, both to alert on and to debug with.
- Decide a cross-provider strategy before you need it: an adapter you maintain, or a gateway that normalizes for you. Anthropic-to-Anthropic failover is free; cross-provider failover needs real translation and its own evals.
- Set a sensible per-model timeout so a hung model spends its budget and yields to the next one rather than freezing the request.
The shape of this list is the same hardening instinct from hardening an AI-generated React app for production, pointed at the runtime model dependency instead of the code the model writes.
Conclusion
The 12 June shutdown was not a one-off. It is a preview of every way a model can leave your dependency graph without warning: a regulatory order, a deprecation notice, a pricing change that makes a model uneconomic overnight. The teams that shrugged it off were not lucky. They had already decided that a model ID is configuration and that every model call goes through one boundary that can fail over.
If you ship one thing from this article, make it the boundary. Start with the thin in-process layer, because it is a few files and it carries no new dependency, and move to a gateway when the provider count justifies the managed routing and the unified observability. Then go further than availability: put your fallback models through the same evals as your primary, because the next outage will test them whether you did or not. The model will change. Your call site should not have to.